To achieve interoperability, systems require standardized and widely accepted methods of communication. This is enabled through the use of standards. Semantic and syntactic standards facilitate meaningful communication by providing a structured framework. HL7 International, established in 1987, has been instrumental in developing these standards. Initially, HL7 focused on creating standards for exchanging admission, discharge, and transfer (ADT) data within hospitals, which were introduced in its first version (HL7 v1) Later, an extension to the standard led to the development of HL7 v2, which has been widely adopted since 1998.
HL7 v2
The HL7 v2 standard facilitates the exchange of clinical data between systems to support patient care. It includes a defined message syntax and data types. Each HL7 v2 message consists of segments containing various fields and is generated by a computer application in response to a specific trigger event. Trigger events, based on real-world scenarios, provide the reason, message type, and structure for generating the message. For instance, the ADT A04 event (“Register a patient”) triggers a message containing all required segments. Once the event is recognized, the application sends a specific message to one or more receiving systems.
Messages are structured with segments containing data fields, which are logically arranged. Fields are divided into components using delimiters such as the field separator (|), component separator (^), and others like (~, , &). Each segment starts with a three-letter header (e.g., MSH for “Message Header”) that identifies the segment type and its data, such as message type, timestamp, and sender information. Empty fields are marked by consecutive separators. Encoding characters are also included in segments to define the message structure

HL7 v3
The phrase “when you have seen one implementation of v2, you have seen one implementation” highlights the main limitation of HL7v2: its lack of standardization. Different implementations handle the same tasks in various ways, making consensus on operational fields and data semantics difficult. Optional fields and segments further complicate consistency, requiring extensive conformance testing.
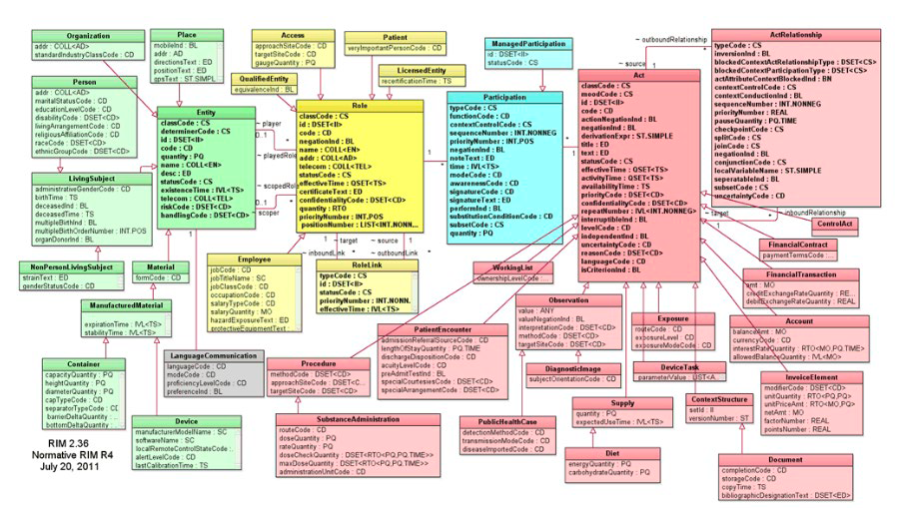
To address these issues, HL7 v3 was developed using the Reference Information Model (RIM) as its foundation. The RIM ensures clear semantics and definitive messaging by employing an object-oriented approach. It organizes information into three core classes—Act, Role, and Entity—and includes a state transition diagram to represent the life cycles of subject classes.While its object-oriented design aimed to improve interoperability, it faced significant challenges. These included complexity, incompatibility with common software development practices, and a lack of direct interoperability with HL7 v2, requiring translation software.
Due to these shortcomings, HL7 v3 was largely overlooked in the U.S. healthcare system under the HITECH Act and meaningful use investments. This prompted the development of the Fast Health Interoperability Resources (FHIR) standard, which leverages modern communication technologies to address the interoperability challenges of its predecessors.
Fast Health Interoperability Resources (FHIR)
In 2011, HL7 decided to create a new standard for interoperability due to the limitations of HL7 v3, which wasn’t widely adopted. They learnt from past standards and other industries to develop FHIR, which uses a more flexible approach based on RESTful APIs. This made it easier to create and implement, as it follows simple internet standards that don’t require complex tools.
FHIR is built on the REST architecture, which uses basic web principles: it manipulates resources with HTTP methods, is stateless, uses simple URLs, and supports data formats like XML or JSON. This makes FHIR efficient, faster to develop, and easy to adopt, since it simplifies the integration process compared to previous standards.
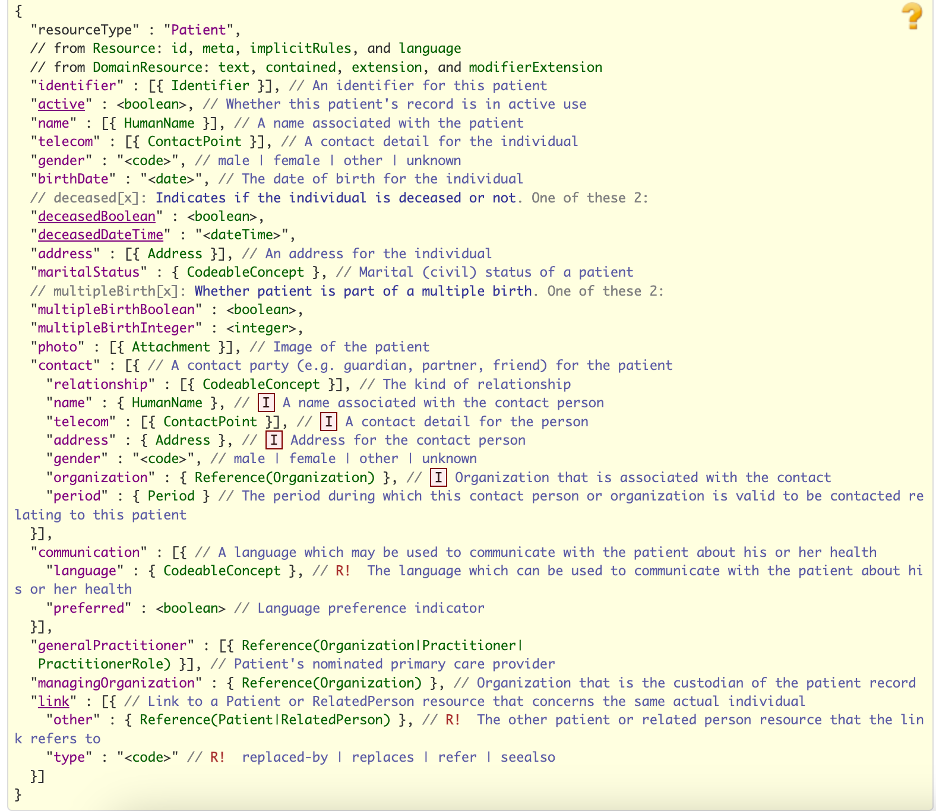
FHIR is made up of “resources,” which are the building blocks for exchanging healthcare data. Each resource has a unique URL and contains information like its ID, type, and version. Resources can be represented in different formats, and they are often used together to create systems that share information. There are over 100 resources, and they are grouped by their level of development and real-world testing. For example, a patient resource can link to other resources like an organization or doctor, forming a network of connected data.
By evolving from HL7 v2 to v3 and finally to FHIR, HL7 has continuously refined its approach to healthcare interoperability, incorporating lessons from each version to create more efficient standards for seamless data exchange and system integration across the industry.